GoodFit overview
Product overview
GoodFit is a service that:
- Collects and models data from many sources, on all viable companies in the world, and the key people (decision makers) within them.
- Data is collected from a large number of data sources, some of which are scraped via public websites, some of which are via commercial means.
- We use this assembled data to build bespoke datasets for clients. These datasets target a specific subset of companies (sourcing criteria) and data points (e.g. the fields the client is interested in). The process of building this dataset is collaborative with the client as our team (our solutions engineers) need to deeply understand what the client is trying to achieve (their go to market strategy) so we can deliver them data to enable that.
- These bespoke datasets are visible in the client app, but the primary way for clients to access it is via their CRM. We have an integrations layer that syncs records into their CRM, taking into account merging records that already exist etc. We also take care to maintain an audit log of all operations on their CRM.
- Once the data is available in their CRM, the client will operationalise the data, e.g. distributing accounts to their sales team using the supplied GoodFit data to eg inform selection and prioritisation of accounts.
System overview
See https://miro.com/app/board/uXjVKi5tMjs=/ and more detailed [https://miro.com/app/board/uXjVJng8uqc=/](domain map).
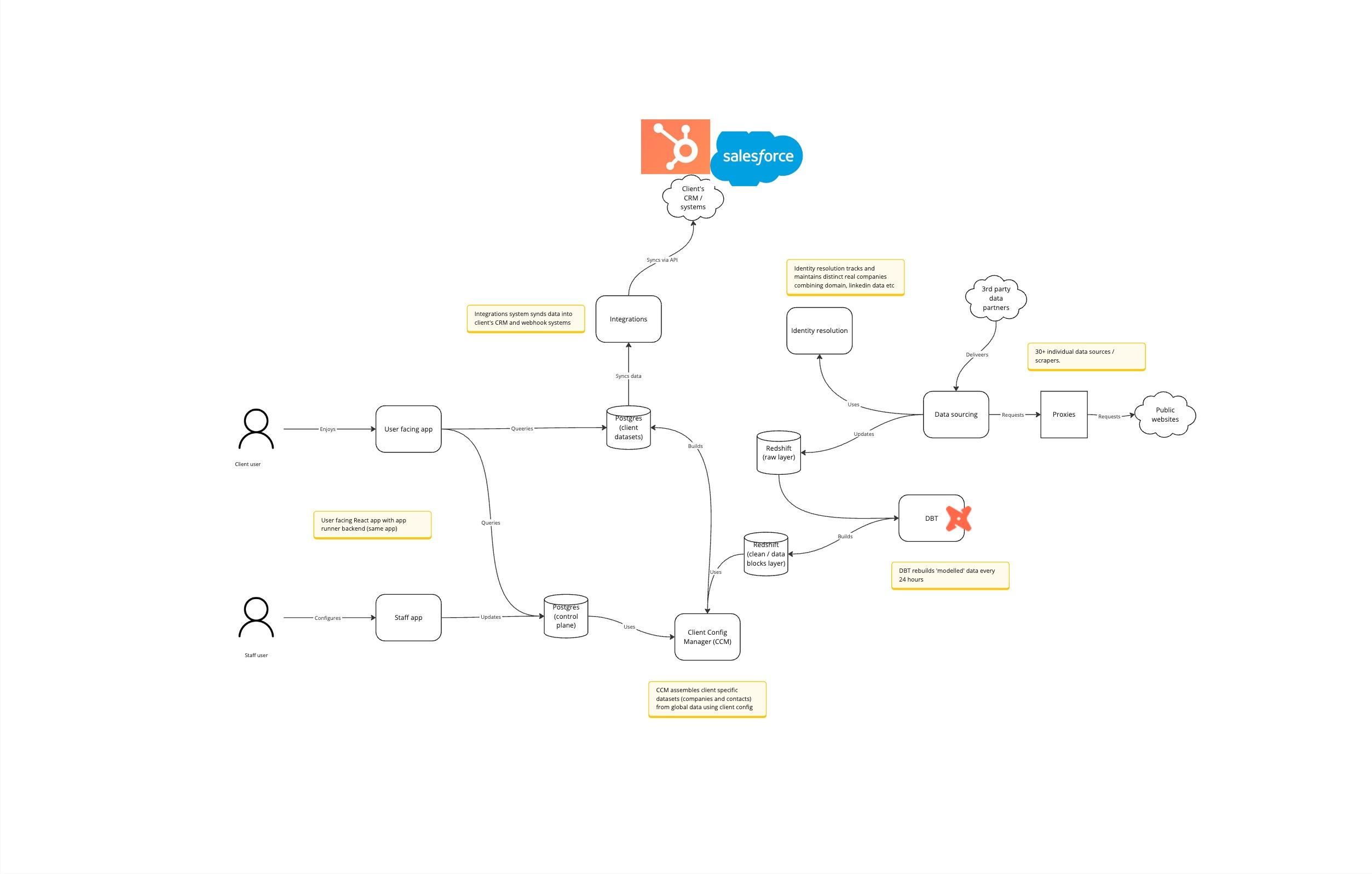
- We operate a large number (30+) of data sources, some of which are scraped via public websites, some of which are via partnerships/commercial arrangements. For scraping we operate a fleet of different proxy providers. We use AWS lambda a lot to process and request data from 3rd part sourcers. Each record in our system has a refresh period which governs how frequently we 'check it', and some sources have 'generators' that iterate new records are they are available. We have a system for monitoring SLOs on refresh rates, and are working on a system for data quality checks to make sure we are collecting data correctly. Collected data ends up in Redshift. See https://miro.com/app/board/uXjVKi5tMjs=/?moveToWidget=3458764599037866504&cot=14
- Data gets combined and merged, using the identity resolution service to map possible identifiers (E.g. domain, linked in id etc) into our internal schema for 'what is a company' (taking into account, e.g. group companies, acquisitions etc).
- We use DBT to process model and combine data from multiple sources into various 'data blocks'. Data blocks are specific to particular domains (e.g. hiring, team, technology) but share the same normalised concept of 'company id' which we use to combine the data. We batch process every 24 hours.
- Once the 'assembled' data blocks is ready, we can assemble the clients datasets. We use the 'client config manager' which is the control plane with which GoodFit staff interact. This allows setting and experimenting with 'sourcing criteria' and 'data points'. Typically in the onboarding process changes are made frequently here until the client is happy, and often during the contract we will make changes. Note that we continuously supply new companies that satisfy the sourcing criteria as we find them in our core dataset. See https://miro.com/app/board/uXjVKi5tMjs=/?moveToWidget=3458764599040856183&cot=14
- Once the client bespoke dataset is built (and it refreshes daily) it is visible in the client facing app. This allows the client to preview and explore the dataset. See https://miro.com/app/board/uXjVKi5tMjs=/?moveToWidget=3458764599037866649&cot=14
- These bespoke datasets are visible in the client app, but the primary way for clients to access it is via their CRM. We have an integrations layer that syncs records into their CRM, taking into account merging records that already exist etc. We also take care to maintain an audit log of all operations on their CRM. This system broadly:
- Queries records that have changed in the clients dataset and exports them as an incremental export into S3
- The S3 file is processed in chunks, using AWS step functions and Lambda. Each chunk is synced to the clients CRM, if possible using batch operations (for speed) depending on the capabilities of the 3rd party CRM (Hubspot / Salesforce).
- We maintain state mapping internal record ID to external integration ID, so we continue to sync the same record to the external system
- There are lots of edge cases here, and we need to account for errors / go slows in the 3rd party system. Fun times!
We also operate other non-core systems:
- Email finder: We use a variety of sources and techniques to 'guess' the best email address for a given decision maker in the organisation so we can supply it to the client. This system currently runs on ECS as a docker container.
- Crawler: As well as scraping some sources, we 'deep crawl' client sites so we can detect page elements (indicating technologies) and other context. We have some use cases that require evaluating Javascript (e.g. GraphQL detection) so use headerless chromium here and puppeteer. We operate a fleet of EC2 machines for efficiency, managed via ECS.
- Predictive labels: We store the embedded webpage text for each company website main page. We have a system that allows people to build machine learning models on these vectors (using SVMs) to classify domains / companies according to textual context on their site (e.g. companies that sell b2b vs b2c, ecommerce vertical, type of finance institution). (the reason this exists is that predefined industry categories are rarely accurate).
Technologies uses
Languages / Code organisation
- Main language is Typescript.
- We use Python when we are dealing with large data processing or machine learning. Pandas (considering Polars), SciKit learn etc.
- We operate a 'semi' monorepo. All backend services are in one repo of multi deployable services. This repo contains both TS and Python code.
- Frontend is a separate repo
- DBT is a separate repo
- We make heavy use of SQL. Not only in DBT for large dataset processing, but also we are not afraid to use SQL in code as opposed to delegating to ORMs. We find ORMs are not good at generating efficient SQL for large datasets. We have a sql template library that allows SQL strings to be assembled using bound parameters, therefore without risk of SQL injection.
Data storage
- We use Postgres for our 'smaller' and 'real time' data. E.g. state that needs quick access or 1:1 row operations. We also store client datasets here as they tend to be small and require low latency access.
- We use Redshift for 'large' data, e.g. on all companies. We store the 'raw' data from sources, and the various layers until we end with out 'data blocks' cleaned modelled later.
- Postgres and Redshift are connected, e.g. we can select data from Redshift from a DBLink query in Postgres, we often use CREATE TABLE AS SELECT FROM dblink for example. We find this to be operationally simple, reliable and faster than exporting via S3.
Infrastructure
- Most systems deploy via the serverless framework (including most that use App Runner or ECS using relevant serverless plugins).
- We try to keep individual systems small and deployable quickly (eg each serverless project).
- Most logic is implemented with AWS Lambda functions.
- We use various supporting technologies, e.g. SQS and Step functions to orchestrate work by Lambdas. We can control these via serverless projects.
- In some cases, Lambdas may invoke other Lambdas, but we prefer using SQS or Step Functions to oversee this.
- We dont use Lambdas for user facing APIs, as the start up latency is slow. We are using AWS AppRunner to host a serverless express app in a Docker container. This works well. We can control these via serverless projects.
- We use ECS for some services were Lambda is not a fit. We can control these via serverless projects.
- We operate separate AWS accounts for dev, dev2, stag and prod.
- Environments are controlled via AWS CDK infra as code. Some older environments include hand built elements, so its a long term project to unify these and make them all managed by CDK.
Deployment / CICD
- We have multiple AWS environments: dev, dev2, stag and prod. Development builds and QA happen in dev/stag before deploying to prod.
- We use Github actions for CI and CD.
- Upon PR we run all tests (with PG database available with correct schema)
- Deploying to each environment is via Github action. User selects which service(s) to deploy.