Debugging sourcers
So your parser threw a tantrum? Let’s calm it down...
Debugging a Parser
Say we have an error like this:
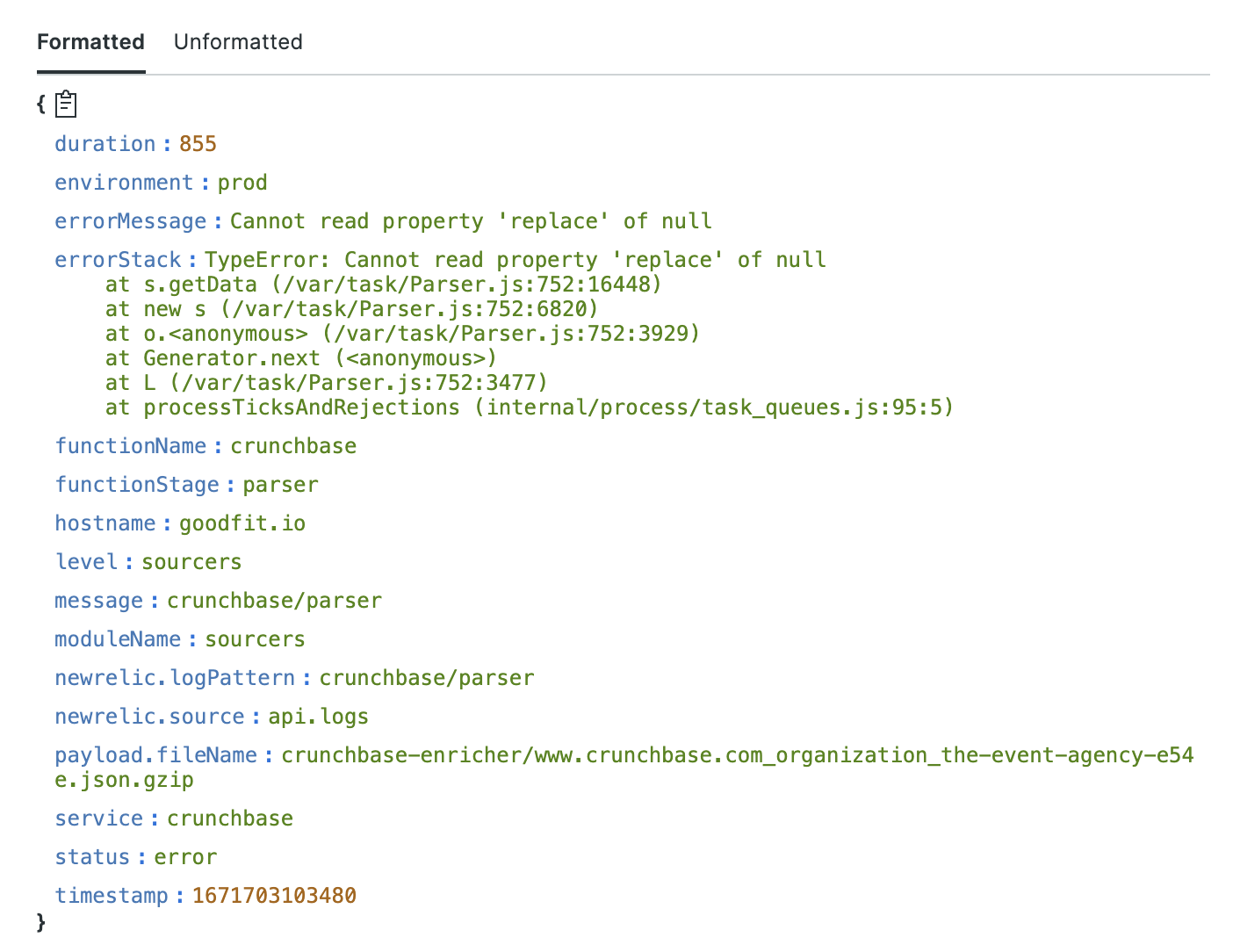
First step is to download the page object and see the HTML.
Sourcing Data is fed into:
- PROD: sourcing-data-prod
TEST: goodfit-sourcer-data-testDeprecated- DEV: gf-sourcer-data-dev
- STAG: gf-sourcer-data-stag
The best way is via the AWS CLI. Copy the payload.filename above into:
AWS_PROFILE=gf-prod aws s3 cp s3://sourcing-data-prod/crunchbase-enricher/www.crunchbase.com_organization_the-event-agency-e54e.json.gzip - | gunzip
(Changing the AWS_PROFILE accordingly)
The above is copying the S3 file to stdout (-) and then gunziping it.
If you want to just get the HTML content of the first item in the file, you can do:
AWS_PROFILE=gf-prod aws s3 cp s3://sourcing-data-prod/crunchbase-enricher/www.crunchbase.com_organization_the-event-agency-e54e.json.gzip - | gunzip | jq -r '.[0].htmlContent'
In this case we can clearly see that issue is being blocked by geo:

Parser Tips
Parsing Values
Each parsed property should return undefined where no value can be found in order to preserve historic values in the parsers table.
This is because we're UPSERT'ing the records when we update them.
null will overwrite any historic values, whereas, undefined properties are skipped in the update.
For this reason, we should always fall back to undefined for unknown values.
Resetting a sourcer
Once you have made your changes and fixed your parser, you will need to reset the parser to allow any records that previously errored to be re-parsed.
-- Replace `crunchbase` with the sourcer name
UPDATE public.crunchbase
SET sourcing_status = NULL
WHERE sourcing_status = 'Error';
Example: Fixing the G2Crowd Sourcer
Debugging a Sourcer can be a bit of a choose-your-own-adventure. Sometimes the Loader is being dramatic, refusing to fetch pages because the isUnavailable logic is tripping over new layout changes. Other times, pages are happily chilling in S3 while the Parser quietly loses its mind trying to make sense of them.
Whatever rabbit hole you end up in, do future-you (and the rest of us) a favour: update this doc as you uncover new paths and pitfalls!
🧭 Source code:
src/services/enrichers/g2crowd
Companies Under Test
We currently run unit tests against these G2 pages:
- www.g2.com/products/lickd/reviews
- www.g2.com/products/hootsuite/reviews
- www.g2.com/products/grc-easy-user-management/reviews
- www.g2.com/products/creo-simulation/reviews
- www.g2.com/products/acasa/reviews
- www.g2.com/products/acadly/reviews
- www.g2.com/products/abs/reviews
- www.g2.com/products/abre/reviews
- www.g2.com/products/123-cheap-domains/reviews
- www.g2.com/products/1-click-ready-windows-tool-sharpdevelop-on-windows-2012-r2/reviews
Test fixtures for these lives here: src/services/enrichers/g2crowd/tests/html
Debugging
1. Grab the Files from S3
These files serve double duty: they’re parsed by the Parser and used as test fixtures.
First, hop into the AWS DEV environment and check when the files were last generated.
🎒 S3 Bucket: gf-sourcer-data-dev/g2crowd-enricher
Pull down the latest page content with:
awss gf-dev && \
for name in hootsuite lickd grc-easy-user-management creo-simulation acasa acadly abs abre 1-click-ready-windows-tool-sharpdevelop-on-windows-2012-r2 123-cheap-domains; do
AWS_PROFILE=gf-dev aws s3 cp \
s3://gf-sourcer-data-dev/g2crowd-enricher/www.g2.com_products_${name}_reviews.json.gzip - | gunzip > www.g2.com_products_${name}_reviews.json
done
Boom, you’ve got fresh files 😎
2. Run the Tests
Check your progress anytime by running the tests:
pnpm run test G2CrowdParser --watch
Start by confirming the Loader is actually pulling in the new pages. Then you can focus on whether the Parser is doing its job… or crying for help.
💡 Remember: reset sourcing_status every time you make Loader changes, otherwise, the Scheduler will skip your companies faster than you can say "boo!" to a goose 🪿.
3. Reset sourcing_status
-- Set sourcing_status to NULL for the companies we care about
UPDATE public.g2crowd_products
SET sourcing_status = NULL
WHERE url ILIKE ANY(ARRAY[
'%lickd%',
'%hootsuite%',
'%grc-easy-user-management%',
'%creo-simulation%',
'%acasa%',
'%acadly%',
'%abs%',
'%abre%',
'%123-cheap-domains%',
'%1-click-ready-windows-tool-sharpdevelop-on-windows-2012-r2%'
]::text[]);
-- Verify the `sourcing_status` is now `NULL` for each company
SELECT * FROM public.g2crowd_products
WHERE url ILIKE ANY(ARRAY[
'%lickd%',
'%hootsuite%',
'%grc-easy-user-management%',
'%creo-simulation%',
'%acasa%',
'%acadly%',
'%abs%',
'%abre%',
'%123-cheap-domains%',
'%1-click-ready-windows-tool-sharpdevelop-on-windows-2012-r2%'
]::text[]);
-- Reset all records in with a sourcing_status of `'Error'` or `'Unavailable'`
UPDATE public.g2crowd_products
SET sourcing_status = null
WHERE sourcing_status = ANY(ARRAY['Unavailable', 'Error']::text[]);
4. Trigger the Scheduler
Running the scheduler causes us to re-fetch fresh copies of the site assets we're using to parse data from.
Fire up the G2Crowd Scheduler Lambda in DEV: Launch Scheduler Lambda
Wait until all your test companies move past "Scheduled" before continuing (see the queries above).
5. Pull New Fixture Assets
Once new pages are fetched, pull down the fresh fixtures again (see Step 1)
Then replace the old fixtures in: src/services/enrichers/g2crowd/tests/html
Now you’ve got shiny new data to dissect any Parser quirks.
6. Make Changes, Rinse & Repeat
Helper scripts (gf_*) can be found in the toolbox.
Think you’ve nailed the Loader fix? Deploy and find out:
cd src/services/enrichers/g2crowd && gf_deploy_function dev Loader
Then rinse and repeat, fetch, test, debug, and deploy until the tests are happy and your sanity returns.
Once confident, do an end-to-end test by deploying the full service & triggering the Scheduler (don't forget that pesky sourcing_status!!):
cd src/services/enrichers/g2crowd && gf_deploy_service dev
🎉 Congrats, you just tamed the G2Crowd Sourcer beast!